文字が全角・半角バラバラでデータベースに登録していませんか?
全角・半角が統一されていないとDISTINCTやGROUP BYを使ってもレコードが一意になりませんよね。文字を検索しても2レコード表示されてしまいます。
BigQueryであればNORMALIZE関数を使うと簡単に全角から半角に直すことができます。
今回は全角を半角に直すNORMALIZE関数について紹介します。
NORMALIZE関数について
NORMALIZE関数は文字列を正規化するための関数です。
正規化するためのオプションが4つあります。
| オプション名 | 正式名称 | 意訳 |
| NFC | Normalization Form Canonical Composition | 対象の文字と同等な文字で正規化する |
| NFKC | Normalization Form Compatibility Composition | 対象の文字と互換性ある文字で正規化する |
| NFD | Normalization Form Canonical Decomposition | 対象の文字と同等な文字で正規化し、複数の結合文字は指定する順番で組み立てる |
| NFKD | Normalization Form Compatibility Decomposition | 対象の文字と互換性ある文字で正規化し、複数の結合文字は指定する順番で組み立てる |
結構難しい英語を使っていたのが意味が通じそうなレベルまで意訳してみました。
基本的には同じような文字で正規化するか互換性がある文字で正規化するか2通りみたいですね。
詳しくは意味や使い方はリファレンスをご確認ください。

全角を半角にしたいときはNFKCオプションを使います。
テストデータを使って処理を確認してみましょう。
テストデータ 〜全角文字列を半角に変換する〜
ここに全角・半角が統一されていないテストデータがありました。
本来であれば3行表示されてほしいですが、GROUP BYしても6行ですね。

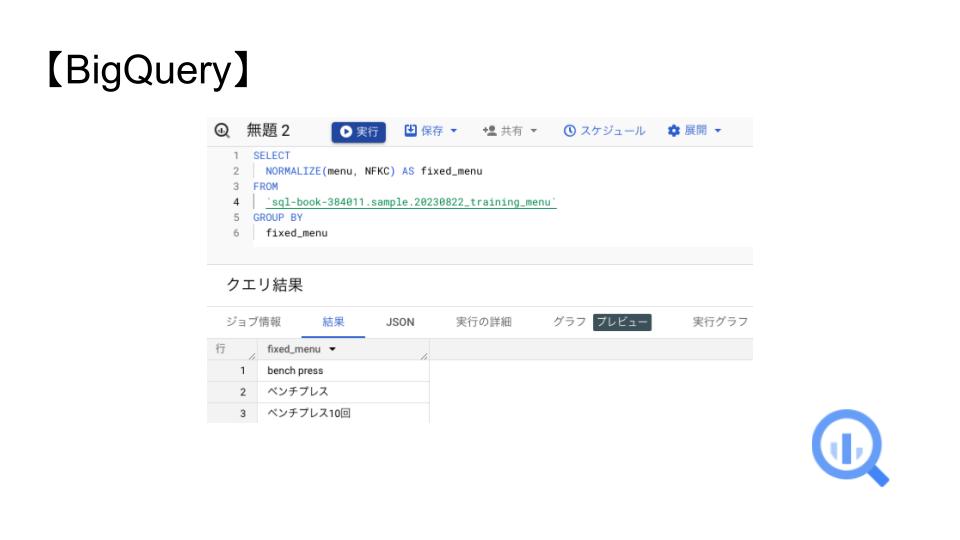
NORMALIZE関数とNFKCオプションを使って半角に統一しましょう。
SELECT
NORMALIZE(menu, NFKC) AS fixed_menu
FROM
`sql-book-384011.sample.20230822_training_menu`
GROUP BY
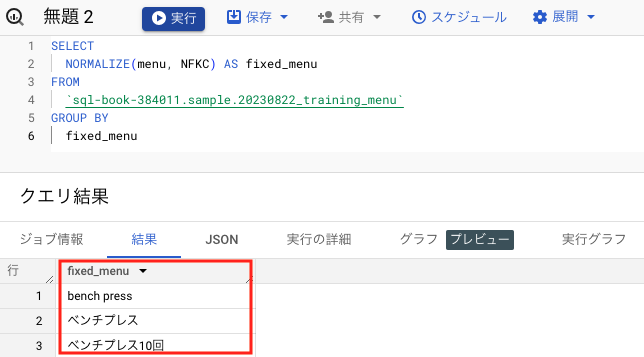
fixed_menu3行に統一できました!
カタカナは半角から全角になりアルファベットと数字は全角から半角になりましたね。
カタカナも半角で統一されるのかな?と思いましたが全角で統一されると分かりました。
アルファベットと数字だけ全角から半角になるのは使いやすいですね!
まとめ
今回は全角文字列を半角に変換するNORMALIZE関数とNFKCオプションについて紹介しました。
数字とアルファベットは全角から半角に変換し、かな文字やカタカナ・漢字は全角に統一してくれるので使いやすいですね。
他にもいくつかオプションがありました。
今回は紹介しきれませんでしたまた試してみたいと思います。
全角・半角を統一する機会があれば是非NORMALIZE関数を使ってみましょう!